
Since November 2022 AI is present in the mainstream: OpenAI published the LLM ChatGPT. Around three years later AI is everywhere: image- and video-generation, translations, audio-plugins and much much more. Hard to believe, but I got in touch with AI 17 years before ChatGPT has been released.
Table of Contents
- Basics of Artificial Neural Networks
- De-Feedback using a SHARC DSP and Neural Network
- Basic design of an adaptive filter with neural network
- Train a neural network to detect feedback
- Testing the filter
During my studies of electrical engineering around 2005, the teachers tried to explain us the usage of so called neural networks in control-loops – that didn’t work out very well. My fellow students and I had some trouble to understand the background. 21 Years later I tried again to get in touch with neural networks and had much more success. I was able to create a real-time De-Feedback-Plugin for a SHARC DSP as well as a multi-input-control for a buck-converter using neural networks. But maybe we should have a short look at the basics of a neural network.
Basics of Artificial Neural Networks
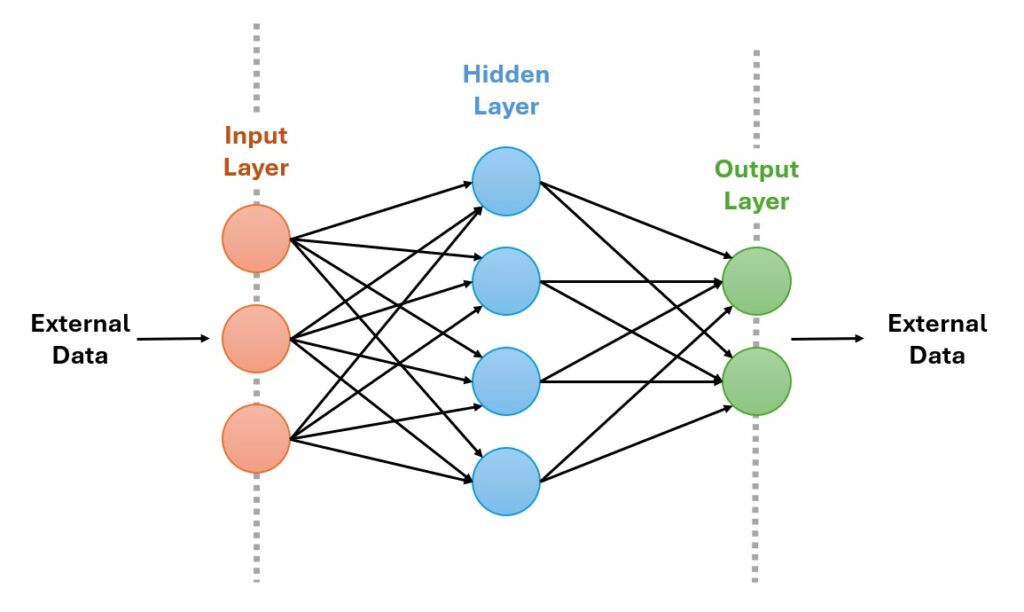
I don’t want to reproduce the Wikipedia-Article here, but in short: an artificial neural network consists of an input layer, a hidden layer and an output layer. The input and output layers are the interface to the “real-world” while the hidden layer is the “brain” of the network. In a common feed-forward network all connections between the individual neurons are unidirectional so that the information is feedforwarded to the next neuron using weighting-factors, the “weights”. So a neuron typically have more than one inputs, but only a single output.
But how can this be used in a control or an audio-application? In this blog-entry I’d like to show you two real-world-examples I developed in March 2026: a multi-modal control for a buck-converter and a De-Feedback-Plugin for a DSP. The control for the buck-converter will get an own blog-post, so have a look at the second part if you are interested. Lets start with the audio-part…
De-Feedback using a SHARC DSP and Neural Network
If you’ve read my other blog-posts or maybe seen my videos about the OpenX32-project you know, that I’m working on an open-source operating system for the Behringer X32 audio-mixing-console. We are at a point where we have full control over the two Analog Devices SHARC DSPs so I thought about new ideas for live-audio-plugins. Since a couple of months the company AlphaLabs made some noise with their AI De-Feedback-plugin that is able to remove direct and indirect feedback in a live application.
So I thought that’s a great idea for a new plugin for our open-source system. But where to start? I tried to get some information about how the plugin is working. It got clear pretty fast, that they are not using the standard DeFeedback-strategy of using an autotuned Notch-filter as the plugin removes some kind of reverb next to the direct feedback. The plugin seems to remove everything that is not recognized as human voice by the AI, a neural network. Therefore it uses a minimum audiobuffer to add no additional latency to the general audio-buffer – so no look-ahead is possible like in offline-processing-tools.
My goal was not to implement a full-featured plugin like the AlphaLabs device, but it should be a kind of auto-volume- or gate-control where the control-source should be the neural network. If this network detects a feedback, it should turn the volume of the channel down – like an inverted gate with “feedback-noise” as control-source. So my goal was clear now: how can an neural network be trained to detect a specific sound or hence a feedback-noise and how can it be processed on a SHARC DSP?
Basic design of an adaptive filter with neural network
It was clear that I had to make some decisions: what kind of specific model should be used, how many neurons are required (the size of the hidden layer), what learning-algorithm is working and last but very important: what kind of training-data is required? To keep the latency as low as possible I wanted to use a sample-by-sample processing like in the other DSP-plugins. As the DSP of OpenX32 is using a buffer-size of 16 samples at 48kHz, this results in 333 microseconds latency – more or less realtime-ish. After reading some pages and talking to Googles Gemini I decided to give a pre-trained feed-forward neural-network with inference a try.
This feed-forward neural network has several neurons, that perform the following equation:
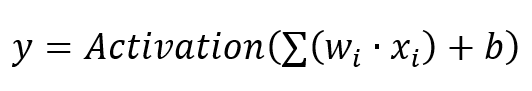
So each neuron has basically a number of inputs x, a multiplication with a weighting-factor and an integrator as well as some kind of bias-value – nothing a ADSP-21371 DSP from 2012 cannot handle as it has native accelerated support for FIR-filters, that have huge amount of multiplications. So the first implementation of a neuron looked like this:
// iterate through all neurons in the hidden-layer
for (int i = 0; i < HIDDEN_LAYER_SIZE; i++) {
// first load the bias for this specific neuron
float sum = nn_bias_h[i];
// now calculate the multiplication of weighting-factor and
// input and integrate the result
for (int s = 0; s < SAMPLES_IN_BUFFER; s++) {
sum += input[s] * nn_weights_ih[i][s];
}
// the last step: is this neuron activated or not?
hidden[i] = (sum > 0.0f) ? sum : 0.0f;
}The activation-function is still missing, but in general thats it. Well, is this already intelligence – at least artificial? I dont know, but this is the core of the whole AI-rush of the last years. Now that we have a working hidden-layer based on the inputs, I had to calculate some output. As my goal was a control-structure for a gate-like-mechanism, a single output would be great that shows me if a feedback happens. This can be done using another set of weighting-factors again:
// some bias for the output
float logit = nn_bias_out;
// calculate a single output-value based on all hidden-layer-neurons
for (int i = 0; i < HIDDEN_LAYER_SIZE; i++) {
logit += hidden[i] * nn_weights_ho[i];
}Logits are the raw outputs from the final layer of the deep learning model. The logit function is the logarithm of the ratio of the probability that an event occurs to the probability that it does not occur:
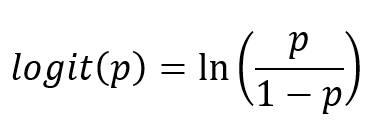
So my goal was to calculate exactly this logit-value based on all neurons in the hidden-layer and afterwards the desired certainty of the signal to be detected as feedback. Here Sigmoid is the activation function that converts the raw logit-output to a final score between 0 and 1. If my pre-trained network (we are getting to this in a second) detects the parameters of a feedback, this value would be high, otherwise low:
float probability = 1.0f / (1.0f + expf(-logit));Based on this probability I should be able to control my audio-gate. If the probability is below a threshold, the gate should be open, otherwise the gate should be closed to mute the feedback – quite harsh method, but hey, this is my first AI-based audio-filter 🙂
float targetGain = 1.0f;
if (probability > INTERVENTION_THRESHOLD) {
// damp the output-signal
targetGain = 0.0f;
}
for (int s = 0; s < SAMPLES_IN_BUFFER; s++) {
audiosamples[s] *= targetGain;
}This method would turnoff the audio very hard and regain it again. So I added an envelope-function like I did for my dynamic-compressor or the standard noise-gate of the OpenX32 audio-processing:
// Last Step: intervention logic with a hard threshold
float targetGain = 1.0f;
if (probability > INTERVENTION_THRESHOLD) {
// damp the output-signal
targetGain = 0.0f;
// fast attack
envelope += 0.1f * (targetGain - envelope);
}else{
// slow release of filter
envelope += 0.01f * (targetGain - envelope);
}
for (int s = 0; s < SAMPLES_IN_BUFFER; s++) {
audiosamples[s] *= envelope;
}After reading more about audio-filters and discussions with a much larger AI, Google Gemini suggested to add an additional FIR-filter to increase the effectiveness of the filter to be able to remove even reverb of the room and just keep the human voice. So I tried to implemented a non-linear adaptive filter that tries to filter out the non-human parts based on the trained network. This adaptive least mean squares, (LMS) filter attempts to calculate the changes the room makes to the signal like delay, reverb and changes in the frequency. The trained neural network is intended to help determining whether a sound picked up by the microphone is coming directly from the person/singer or is a copy of the speaker signal that should be damped, removed (muted). This is my first approach of such a non-linear adaptive filter:
// set a maximum learning-factor for the adaptive filter
float mu_max = 0.001f;
// high probability of feedback results in high
// learning of the adaptive filter and vice versa
float current_mu = probability * mu_max;
for (int n = 0; n < SAMPLES_IN_BUFFER; n++) {
// simple FIR Filter for prediction
float pred = 0;
for(int i = 0; i < TAPS; i++) {
pred += weights[i] * history[i + (SAMPLES_IN_BUFFER - 1 - n)];
}
float error = input[n] - pred;
output[n] = error;
// filter update
float energy = 0;
for(int i = 0; i < TAPS; i++) {
float h = history[i + (SAMPLES_IN_BUFFER - 1 - n)];
energy += h * h;
}
energy += 0.01f; // small bias to prevent a DIV/0
float step = current_mu / energy;
// update of the weights
for (int i = 0; i < TAPS; i++) {
weights[i] = (weights[i] * LEAKAGE) + step * error * history[i + (SAMPLES_IN_BUFFER - 1 - n)];
}
}
// update the history for this filter
memmove(&history[SAMPLES_IN_BUFFER], &history[0], TAPS * sizeof(float));
for (int i = 0; i < SAMPLES_IN_BUFFER; i++) {
history[SAMPLES_IN_BUFFER - 1 - i] = output[i];
}So the neural network acts more like an observer that tries to recognize the desired patterns of the feedback, while the adaptive filter is the worker that performs the mathematical calculations to reduce feedback (and maybe reverb). As shown in line 6 of the above code the neural network controls the learning-rate of the LMS-filter so this filter interacts only on higher certainties of the neural network.
Train a neural network to detect feedback
The Wikipedia-article about neural networks had a good hint for training such networks: use Python together with PyTorch to train neurons for a specific task. PyTorch is an open source deep learning framework used to build neural networks, combining the machine learning library of Torch with a Python-based high-level API. In the Wiki-Article some examples were shown as well. Based on this I created a Python-script that initializes Torch:
class DeFeedbackNet(nn.Module):
def __init__(self, input_size=16, hidden_size=32):
super(DeFeedbackNet, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, 1)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
Here I initialized Torch with an input-size of 16 (16 audio-samples) and a hidden-size of 32. Why? I just used some smaller numbers here as higher numbers would increase the total numbers of multiplications in the plugin. I hoped for the best :-). Some documentations suggested the ReLU function for the beginning. Relu is an activation function that is defined as this: relu(x) = { 0 if x<0, x if x > 0}, so this should fit my implementation in C as well.
Now it was time to think about some training-data before thinking about how to implement the training itself. So first I searched for some demo-recordings that were sharp, clean and without reverb:
Then I added some nasty beeps with different frequencies into the recording without changing the length of the recording:
So now I had two training-recordings and one clean reference. Now back to PyTorch. Using the module “torchaudio” it was very simple to load wave-files into Python, slice them into blocks of 16 samples and feed them into torch using the command torch.cat(…):
def prepare_multi_data(file_pairs, block_size=16):
all_x = []
all_y = []
for dry_path, disturbed_path in file_pairs:
print(f"Loading: {dry_path} / {disturbed_path}")
clean, _ = torchaudio.load(dry_path)
disturbed, _ = torchaudio.load(disturbed_path)
min_len = min(clean.shape[1], disturbed.shape[1])
clean = clean[0, :min_len]
disturbed = disturbed[0, :min_len]
num_blocks = min_len // block_size
# slice into blocks
x_clean = clean[:num_blocks*block_size].view(num_blocks, block_size)
x_dist = disturbed[:num_blocks*block_size].view(num_blocks, block_size)
all_x.append(x_clean)
all_x.append(x_dist)
# Labels: 0 for clean, 1 for feedbacked
all_y.append(torch.zeros(num_blocks, 1))
all_y.append(torch.ones(num_blocks, 1))
# merge everything into one large tensor
x = torch.cat(all_x, dim=0)
y = torch.cat(all_y, dim=0)
# shuffle
indices = torch.randperm(x.size(0))
return x[indices], y[indices]
For the real training with PyTorch I had to think about two more parameters: the learning-rate and the number of epochs I’d like to use. One epoch means every sample in the training dataset has been passed through the neural network exactly once. So, repeating the training process over multiple epochs allows the model to refine its internal parameters (the weights and biases), gradually improving accuracy – like in school many years ago 😉 Too few epochs can lead to underfitting, where the model has not learned the patterns sufficiently – umm, or my knowledge in chemistry in school. But too many epochs can cause overfitting, where the model learns the noise in the training data rather than the underlying patterns, resulting in poor performance on new data. Oh man, quite hard to find the right numbers here and the internet says: “The ideal number of epochs is often found empirically”. Great.
Here is my first setup of the training-function:
def train_model_multi(file_pairs):
model = DeFeedbackNet()
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
inputs, labels = prepare_multi_data(file_pairs)
batch_size = 64 # use batches for more stable training
num_batches = len(inputs) // batch_size
for epoch in range(50):
for i in range(num_batches):
start = i * batch_size
end = start + batch_size
batch_x = inputs[start:end]
batch_y = labels[start:end]
optimizer.zero_grad()
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
if (epoch + 1) % 5 == 0:
print(f"Epoch {epoch+1}, Avg Loss: {epoch_loss/num_batches:.4f}")
So this function trains my neural network in batches of 64 with a learning-rate of 0.001 and the files from torchaudio as inputs. The loss is output every 10 epochs which is an indicator for the learning-process: if the loss is decreasing noticeably, the learning is good. If the loss is staying at a high rate or not reducing any more, the training has a problem. Here is an example of one of my trainings:
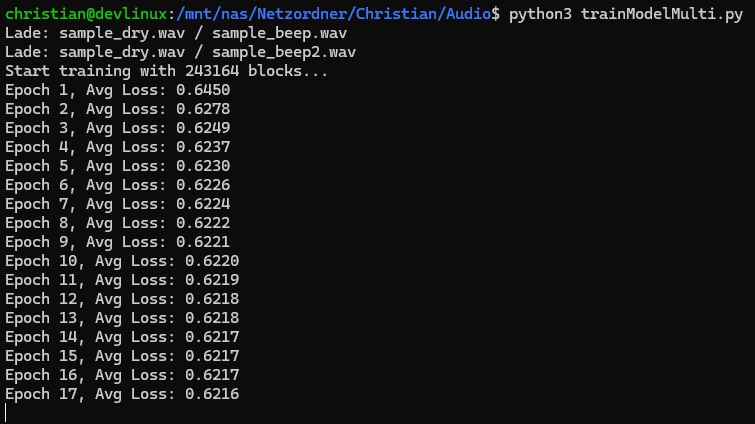
On the first glance this training seems not to reduce the loss very fast, but this seems to be dependent on the input-data as well. In the end, PyTorch returns a model, from which I could read the individual parameters for the neural network:
weights_Input2Hidden = model.fc1.weight.data.numpy()
bias_Hidden = model.fc1.bias.data.numpy()
weights_Hidden2Output = model.fc2.weight.data.numpy().flatten()
bias_Output = model.fc2.bias.data.numpy()[0]Finally I was able to export these coefficients into a header-file for the SHARC DSP:
If you like, you can have a look into the full sourcecode here: OpenX32 DeFeedback with Neural Network. Here the general signal-flow is like this:
- The plugin is initialized as a class using the virtual FxSlot, a Fx-Base-Class
- As parameter a set of pointers for the input- and output-buffer is handed over
- the process()-function is called when 16 samples have been collected using the DMA-receiver of the TDM-serial-port
- the input-signal is preprocessed using a limiter and a makeup with +12dB to make sure the signal is loud enough for the network
- in Line 116 the neural network is called finally
- in Line 122 the non-linear filter is processed together with the prediction of the network
- in Line 157 the feedback-gate is implemented when the network is absolutely certain about the feedback
The SHARC DSP uses around 7% of its ressources for this neural network and the LMS-filter which means, the filter-coefficients could be even larger than the current 32 neurons in the hidden-layer, but for now this is a very nice starting point, because now its time to test this neural network with real input.
Testing the filter
The following audio was recorded using a Behringer X32Rack with our open-source software OpenX32. I connected the microphone to one of the internal XLR-inputs, routed the audio to DSP1, forwarded it to DSP2 and processed the audio. This new audio was then sent back to DSP1 and forwarded to the expansion card using an X-LIVE USB-card. Goldwave then was used to record the audio. But this means, everything you can here in the following demonstration can be used live as well, without any additional latency above the 333 microseconds:
As this was my very first “real” interaction with a neural network – besides the first encounter at the university – I’m very glad that the plugin is working as expected. Sure, there is room for improvement, but now I understood the basics of training a neural network and I’m able to use it in a real-world-realtime-scenario.
…and the best: test it yourself. If you have an X32 audio-mixing-console, download the Alpha 4 of OpenX32 from the GitHub page. You can test it without changing the original firmware, just by booting the firmware from an USB-thumbdrive. Admittedly the setup of the signal-routing is still a bit cumbersome, but you can route one of the inputs to the DSP2, select the DeFeedback plugin and forward this signal back to one of the outputs and you can reproduce my test by yourself.